
はじめに
本番環境で障害が発生!調査のためにS3に出力されているアクセスログやエラーログ(CSVやJSON)を確認したい。 しかし、そのログファイルは数GBの巨大サイズ。
「とりあえず手元にダウンロードしよう……(数分待たされる)」
「ダウンロード完了!エディタで開こう……(PCのメモリを食い尽くしてエディタがフリーズ)」
こんな悲しい経験、エンジニアなら一度はあるのではないでしょうか。
ログの全量が必要なわけではなく、「特定のエラーID」や「特定の時間帯」の数行が見たいだけなのに、ファイル全体をダウンロードして開くのは時間も通信量も無駄ですよね。
調べてみたところ、S3にはファイル全体をダウンロードすることなく、S3側でSQLを叩いて必要なデータだけを抽出してくれる「S3 Select」という神機能があるとのこと。
今回はこの機能を使って、巨大なCSVファイルからピンポイントでログを検索・抽出する設定をやってみました。
今回の要件(やりたいこと)
- 対象ファイル: S3にアップロードされた巨大なアクセスログファイル(access_log.csv)
- 形式: カンマ区切りのCSVファイル(1行目はヘッダー)
- やりたいこと: CSVの「status」列が「500」になっているエラーログの行だけを抽出して画面に表示する
さっそく検索してみた
AWSマネジメントコンソールからS3を開き、対象のログファイルが置かれているバケットに移動します。
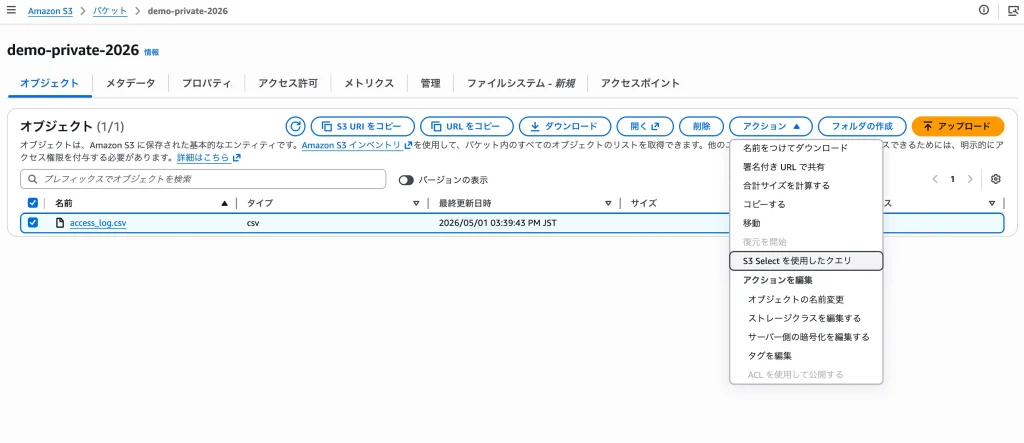
1. S3 Selectの画面を開く
オブジェクトの一覧から対象のファイル(access_log.csv)の左側にあるチェックボックスにチェックを入れます。
画面上部にある「アクション」ボタンをクリックし、ドロップダウンメニューから「S3 Select を使用したクエリ」を選択します。
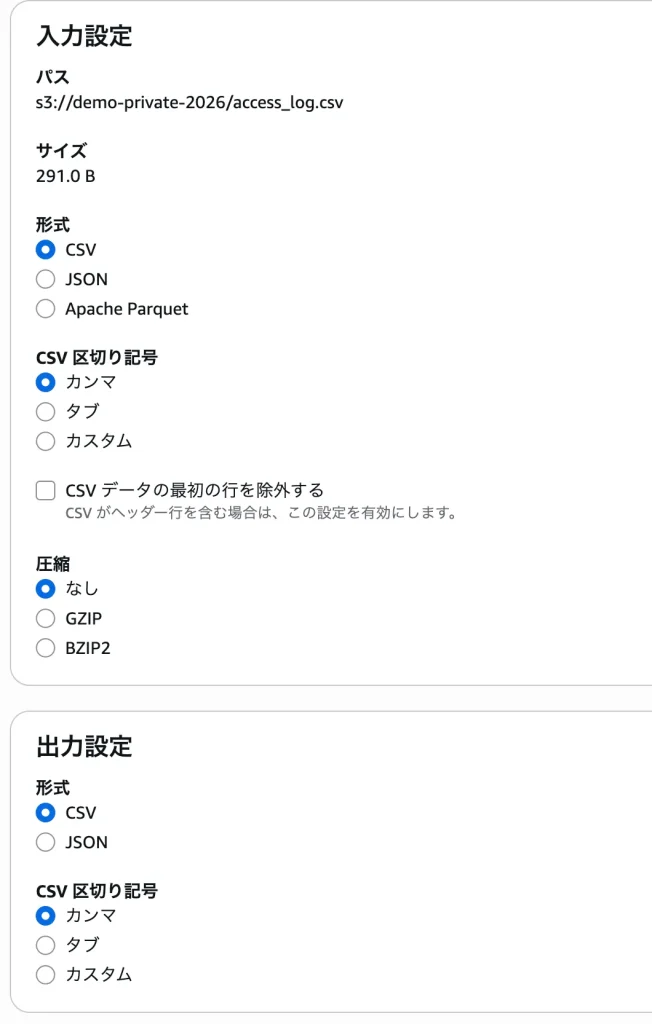
2. まずは入力・出力形式を設定する
クエリ画面が開いたら、まずは「このファイルがどんな形式か」をS3に教えてあげます。
- 入力設定: 形式は「CSV」を選択し、CSV 区切り記号は「カンマ」を選択します。
- 最初の行の除外: 実はここが後で重要になるのですが、最初は「CSV データの最初の行を除外する」のチェックは外したままにしておきます。
- 圧縮: 「なし」を選択します。
- 出力設定: 検索結果をどう表示するか選びます。画面上で確認しやすいように形式は「CSV」、区切り記号も「カンマ」のままにしておきます。
3. 巨大ファイルの「列順」をカンニングする
さて、いざ検索しようと思ったのですが、ここで一つ問題が。
「そもそも、この巨大なCSVファイルの何列目が status なのか分からない……」
S3 Selectでは、コンソールから検索する場合 s.status のような列名(ヘッダー名)での指定ができず、s._1 や s._2 のように「左から何番目の列か」で指定する仕様になっています。
わざわざ中身を見るためにダウンロードしたら本末転倒です。そこで、S3 Selectの LIMIT 句を使って最初の1行(ヘッダー行)だけを抽出してカンニングすることにしました。
- 入力設定: 「CSV データの最初の行を除外する」のチェックは外したままにする。
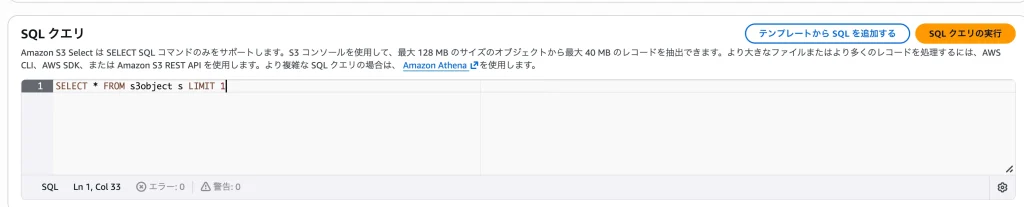
- SQLクエリ:
SELECT * FROM s3object s LIMIT 1と入力して実行。
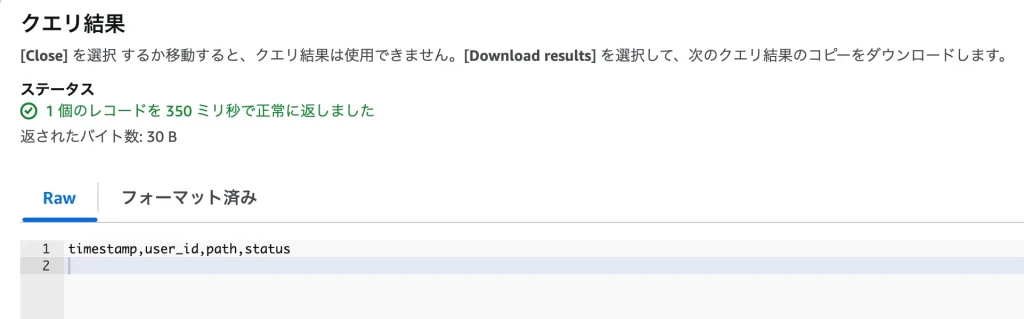
結果が一瞬で返ってきました! 抽出された1行目を見ると timestamp,user_id,path,status となっており、status列は「左から4番目(s._4)」であることが分かりました。
このテクニック、実務でめちゃくちゃ使えます。
4. ターゲットの行を抽出する(本番クエリ)
列の番号が分かったので、いよいよ本番の検索です。
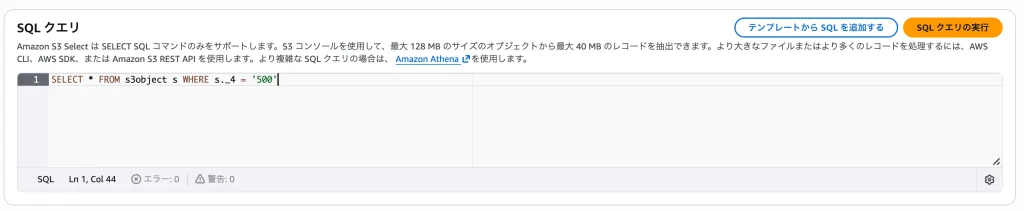
・入力設定: 今度はヘッダー行が検索結果に混ざらないよう、「CSV データの最初の行を除外する」にチェックを入れます。 ・SQLクエリ: 以下のように、4列目(s._4)が500のものを探す条件に書き換えます。
SELECT * FROM s3object s WHERE s._4 = '500'
書き換え終わったら、「クエリの実行」ボタンをクリックします!
5. 検索結果を確認!
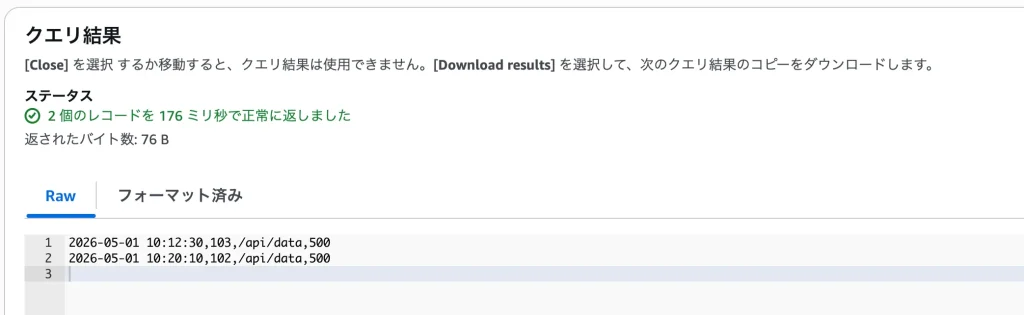
ボタンを押して数秒待つと……画面の下部に「クエリ結果」が表示されました!
数GBあるCSVの中から、ステータスが500になっている行だけが綺麗に抽出されて出力されています。
手元にダウンロードして、エディタを開いて、検索窓で「500」を検索して……とやっていたら数十分かかっていたかもしれない作業が、ブラウザ上の操作だけでものの数秒で完結してしまいました。
これは感動的です。
おわりに
列名で直接検索できない(s._4のように番号指定が必要)というS3 Select特有のクセには少し焦りましたが、「LIMIT 1で先頭だけプレビューして確認する」という回避術を使えば全く問題ありませんでした。
もちろん、複数ファイルにまたがる複雑な集計や定期的なログ分析を行うならAmazon Athenaなどを使うべきですが、「今すぐこのファイルの、この時間帯のエラーだけ見たい!」といった単発のトラブルシューティングにおいては、S3 Selectは最強の時短ツールになります。
追加のインフラ構築も不要で、S3のコンソール画面からいますぐサクッと使える機能なので、巨大なCSVやJSONと日々格闘しているエンジニアの方はぜひ試してみてください!




