はじめに
現場に設置する IoT 機器は、開発環境と違い「人がすぐ触れない」「急な停止がそのまま損失につながる」という制約があります。特にカメラやセンサーを常時稼働させる構成では、通電はされているのに OS が落ちる/固まる、ネットワークが途切れる、プロセスが停止する……といった“地味に困る停止”が一定確率で発生します。
本記事では、親機(ゲートウェイ)×子機(カメラ/センサーノード)というよくある構成を例に、追加ハードに頼らずに導入できる 最小構成の死活管理(自動再起動・復旧) をまとめます。狙いは「現場へ行かなくても戻る」「落ちたことに気づける」「原因が追える」を満たすことです。
想定する構成(汎用モデル)
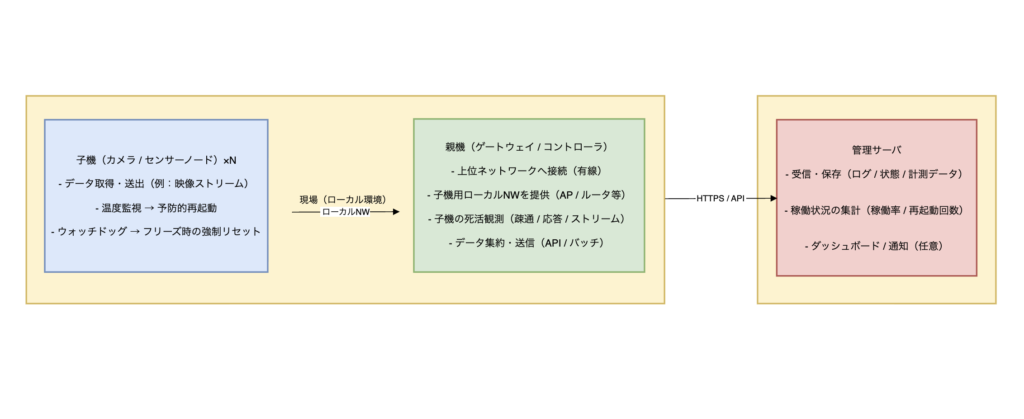
本記事の前提は、現場側に子機を複数台配置し、親機がそれらを収容・集約しつつ、外部の管理サーバへ送信する構成です。
構成図(親機×子機×N台+管理サーバ)
現場で起きる停止パターン(よくある3分類)
現場の停止は大きく次の3種類に分かれます。
- 熱・負荷による不安定化:室温・筐体・設置環境の影響で温度が上がり、処理が不安定になって停止する。“なんとなく調子が悪い”の後に落ちるケースが多い。
- OS/プロセスのフリーズ(ハング):SSH も効かず、ログも取りづらく、アプリ再起動も効かない状態。現場ではこれが最も厄介。
- ネットワーク断・片系断:子機は動いているが親機へ届かない、親機は動いているが外部へ出られない等。“生死”と“通信可否”がズレて切り分けが難しくなる。
解決方針:自己復旧+運用導線(3層)
停止をゼロにするより、止まる前提で復旧させる方が現実的です。本記事では、次の3層で設計します。
レイヤ1:温度監視 → 予防的再起動(兆候への対処)
熱で不安定になってから固まる前に、子機が自発的に再起動して復旧する。
レイヤ2:ウォッチドッグ → 強制リセット(フリーズへの対処)
OSが固まってしまった場合は、ウォッチドッグのタイムアウトで強制リセットする。“OSが動いている前提”ではないのがポイント。
レイヤ3:親機による観測と記録(落ちたことに気づく)
子機が落ちた瞬間、子機は自分で報告できません。そこで親機が 疎通・応答・ストリームを定期チェックし、管理サーバへ状態を送って「運用として気づける」ようにします。
復旧フロー(全体像)
以下のフローで「兆候→予防」「フリーズ→強制復旧」「親機で検知」をカバーします。
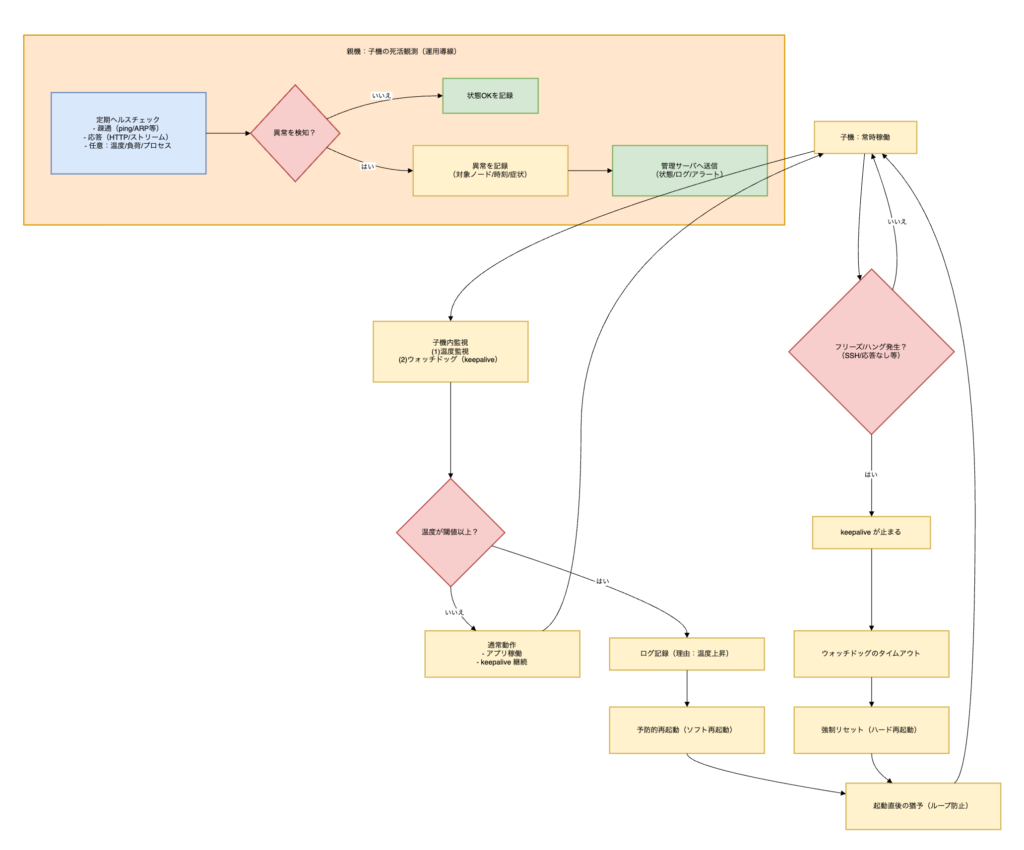
実装の要点(子機側)
子機側の実装は「予防的再起動」と「フリーズ時の強制復旧」を組み合わせます。ここでは Linux + systemd 環境を前提とした、最小構成の考え方をまとめます。
1) 温度監視→再起動(予防的再起動)
温度取得はデバイス/OS に依存しますが、基本は以下の構造です。
- 一定間隔で温度を取得
- 閾値を超えたらログを残して再起動
- 再起動ループ防止のため、起動直後は監視開始を遅らせる
例(概念):
#!/usr/bin/env bash
THRESHOLD=80 # ℃(環境に応じて調整)
INTERVAL=5 # 秒
BOOT_DELAY=120 # 起動直後の猶予(ループ防止)
sleep "$BOOT_DELAY"
while true; do
temp="$(get_cpu_temp)" # ← 環境に合わせて温度取得処理を実装
if [ "$(echo "$temp >= $THRESHOLD" | bc -l)" -eq 1 ]; then
logger -t temp_guard "CPU temp ${temp}°C >= ${THRESHOLD}°C : rebooting"
systemctl reboot
sleep 60
fi
sleep "$INTERVAL"
doneポイント
BOOT_DELAYは「低い閾値で検証する時」や「暑い環境」での再起動ループを防ぎます。- 監視間隔は 5〜10秒程度で十分です。
- 再起動理由を
loggerで残すと、後で原因が追いやすくなります。
このスクリプトは、手動実行で1回だけ検証してから常駐化すると安全です(検証中のループを避けられます)。
2) ウォッチドッグ(フリーズ時の強制リセット)
温度監視は OS が動いている前提です。OSそのものが固まるケースに備え、ウォッチドッグを有効化します。
systemd を使う場合は system.conf に以下を設定します(概念例)。
RuntimeWatchdogSec=10s
ShutdownWatchdogSec=15sRuntimeWatchdogSec は通常運用中のフリーズ検知(目安 10〜12 秒)。ShutdownWatchdogSec はシャットダウン中のハング検知(任意)です。
ウォッチドッグは “keepalive が止まったら強制リセット” なので、温度監視のような「OS上の仕組み」と干渉しにくく、組み合わせに向きます。
実装の要点(サービス化)
温度監視は常駐が必要なので、systemd でサービス化するのが運用上シンプルです。
ユニット例(概念):
[Unit]
Description=Reboot node when CPU temperature exceeds threshold
After=multi-user.target
[Service]
Type=simple
ExecStart=/usr/local/bin/temp_guard.sh
Restart=always
RestartSec=2s
Nice=10
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=multi-user.targetRestart=alwaysにより、プロセスが落ちても自動で復旧します。- ログは
journalに集約され、原因追跡がしやすくなります。
親機側の運用導線(観測・記録・送信)
子機が落ちた場合、子機自身は報告できません。そこで親機が「落ちたことに気づく」役割を持ちます。
観測項目のおすすめ(優先度順)
- 疎通:ping/ARP 等(ネットワーク生存確認)
- 応答:HTTP 応答、ストリーム応答等(アプリ生存確認)
- 任意の指標:温度、ロード、主要プロセスの有無(取れる範囲で)
結果を親機にログとして残し、必要なら管理サーバへ送っておくと「いつ」「どの子機が」「どんな症状で」落ちたかが追いやすくなります。
動作検証の進め方(最低限)
現場向けの仕組みは「動いているつもり」が一番危険です。最低限、以下は押さえると安心です。
- 温度閾値を一時的に下げ、温度監視→再起動が確実に起きること
- ウォッチドッグが有効で、keepalive が動作していること
- 親機が子機の疎通/応答を定期観測でき、異常を記録できること
まとめ:最小構成でも“止まっても戻る”は作れる
親機×子機の現場 IoT では、停止は避けきれません。重要なのは「止まった時に戻る」「落ちたことに気づく」「原因を追える」ことです。
- 温度監視による予防的再起動:不安定化する前に戻す
- ウォッチドッグによる強制リセット:完全フリーズでも戻す
- 親機による観測・記録・送信:運用として気づける/追える
この3点を入れるだけでも、現場への再訪・手動復旧の回数を大きく減らし、継続運用のコストを下げられます。